알고리즘 - 병합 정렬(Merge Sort)의 개념과 특수한 문제 활용법
병합정렬은 전형적인 분할 정복(divide and conquer) 알고리즘의 하나입니다.
주어진 리스트를 병합정렬할 때, 일단 최소단위까지 나누어 놓은 뒤 (분할),
다시 그들을 합치면서 정렬하기 때문입니다.
병합정렬(머지소트)의 과정
- 초기 상태에 정렬되지 않은 리스트가 주어집니다.
- 이 전체 리스트를, 두 개의 리스트가 되도록 분할합니다. -
divide - 그 다음, 분할한 부분 리스트를 정렬합니다. - conquer
- 정렬된 부분 리스트들을 하나의 리스트에 병합(merge)합니다. -
combine
병합 정렬의 과정을 위키백과가 아주 보기 쉽게 나타내었습니다.
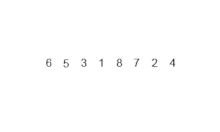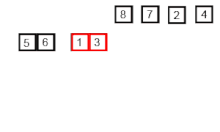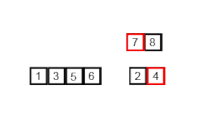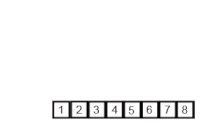
- 초기 상태의 리스트 하나를 두 개의 리스트가 되도록 분할해 나가면서, 최종적으로 길이가 1이 될때까지 분할합니다.
- 초기 리스트가 위 그림처럼 6 5 3 1 8 7 2 4 였을 경우, {6}{5}{3}{1}{8}{7}{2}{4} 로 분할됩니다.
- 먼저 { 6 } { 5 } 를 가져옵니다. 그리고 오름차순 정렬하여 하나의 리스트에 병합하면 { 5 6 } 이 됩니다.
{ 3 } { 1 } 도 { 1 3 } 이 되고, { 8 } { 7 } 과 { 2 } { 4 } 도 각각 { 7 8 } , { 2 4 } 로 길이가 2인 부분 리스트가 됩니다.
- 이제 길이가 2인 부분 리스트들을 길이가 4인 부분 리스트가 되도록, 정렬하면서 병합합니다.
- { 5 6 } 과 { 1 3 } 을 정렬하여 병합하면 { 1 3 5 6 } 이 됩니다.
- 5와 1을 비교 - 1이 더 작으므로, 1이 결과 리스트에 먼저 들어갑니다.
- 5와 3을 비교 - 3이 더 작으므로, 3이 결과 리스트에 들어갑니다.
- 이미 오른쪽 리스트는 다 살펴보았으므로, 왼쪽 리스트에 남은 값을 차례로 결과 리스트에 넣습니다.
- 그러면 최종 결과는 1 - 3 - 5 - 6 순으로 들어가게 됩니다.
- { 7 8 } 과 { 2 4 } 를 정렬하면서 병합하면 { 2 4 7 8 } 이 됩니다.
- 7과 2를 비교 -> 2가 더 작음 -> 2를 결과 리스트에 넣는다.
- 7과 4를 비교 -> 4가 더 작음 -> 4를 결과 리스트에 넣는다.
- 남은 7, 8을 결과 리스트에 차례로 넣는다.
- 결과 리스트에는 2 - 4 - 7 - 8 순으로 들어가게 됩니다.
- { 5 6 } 과 { 1 3 } 을 정렬하여 병합하면 { 1 3 5 6 } 이 됩니다.
즉, 왼쪽과 오른쪽 리스트의 원소를 하나씩 비교하는데, 더 작은 것을 결과 리스트에 넣습니다.
그리고 결과 리스트에 들어가지 못한 리스트의 인덱스를 가리키는 것은 그대로 두고,
결과 리스트에 들어갔던 리스트의 인덱스를 가리키는 것은 한 칸 증가시킵니다.
그리고 그 두 숫자를 다시 비교합니다. 이 과정을 반복하면, 결과 리스트에 정렬되어 값이 들어가게 됩니다.
예 : { 5 6 } 과 { 1 3 } 을 정렬하면서 병합하는 과정


- 이제 길이가 4인 부분 리스트들을 길이가 8인 부분 리스트가 되도록, 정렬 후 병합합니다.
- { 1 3 5 6 } 과 { 2 4 7 8 } 을 정렬하면서 병합하면, { 1 2 3 4 5 6 7 8 } 이 됩니다.
- 1과 2를 비교 - 1이 더 작으므로, 1을 결과 리스트에 넣는다.
- 왼쪽의 3과 오른쪽의 2를 비교
- 왼쪽의 3과 오른쪽의 4를 비교
- ….
- { 1 3 5 6 } 과 { 2 4 7 8 } 을 정렬하면서 병합하면, { 1 2 3 4 5 6 7 8 } 이 됩니다.
- 위 그림과 같은 부분 과정을 처음 리스트의 길이만큼 다시 정렬되어 만들어질 때까지 반복하게 됩니다.
이렇게 병합 정렬을 구현하여 사용하면, 시간 복잡도는 O(nlog_2 n) 이 됩니다.
O(n^2) 보다 좋은 성능을 보이므로 selection sort, bubble sort 등보다 좋은 성능을 보일 수 있습니다.
그러나 위에서 보시다시피, 정렬할 자료를 배열로 구성하게 된다면, 과정에 임시로 결과를 저장하는 배열이 따로 또 필요하기 때문에 메모리 자원 측면에서는 비효율적일 수 있습니다.
소스코드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
#include <iostream>
#define N 10000 // 원하는 원소의 갯수
using namespace std;
int arr[N];
int result[N];
void merges(int left, int right) {
int mid = (left + right) / 2;
int i = left;
int j = mid + 1;
int k = left;
while (i <= mid && j <= right) {
if (arr[i] > arr[j]) {
result[k++] = arr[j++];
}
// 양쪽 리스트에서 최솟값을 비교했는데 오른쪽 리스트가 더 컸을 경우
// 그대로 왼쪽 리스트의 최솟값이 결과배열에 내려오면 됩니다.
else {
result[k++] = arr[i++];
}
}
// 오른쪽 리스트에 아직 결과배열에 들어가지 못한 값이 있으면 그대로 넣어줍니다.
if (i > mid) {
while (j <= right) {
result[k++] = arr[j++];
}
}
else { // 그림의 (6)번 과정
while (i <= mid) {
result[k++] = arr[i++];
}
}
// 다시 원래 배열에 옮겨담는 작업
for (int a = left; a <= right; a++) {
arr[a] = result[a];
}
}
void partition(int left, int right) {
int mid;
// 두개로 분할하고, 병합하는 과정
// 병합 함수 merges를 보면 알 수 있듯이, while문 등으로 정렬하면서 병합하게 된다.
if (left < right) {
mid = (left + right) / 2;
partition(left, mid);
partition(mid + 1, right);
merges(left, right);
}
}
int main() {
int N;
cin >> N;
for (int i = 0; i < N; i++) {
cin >> arr[i];
}
partition(0, N - 1);
// 이후 결과 배열인 result를 출력하거나 활용하면 됩니다.
return 0;
}
사실 알고리즘 문제를 풀 때, 위의 병합 정렬 소스코드를 직접 짜서 자료를 정렬할 일은 거의 없습니다.
C++ STL 에서 제공하는 sort 함수가 매우 강력하고 편하기 때문입니다.
하지만, 이 병합 정렬을 직접 짜서 문제를 풀어야 하는 경우가 있는데, 바로 아래 문제입니다.
백준 1517번 : 버블 소트 - https://www.acmicpc.net/problem/1517
문제는 버블 소트라 머지 소트(병합 정렬) 관련이 없어 보이지만 실제 풀이에서는 시간 복잡도 때문에 버블 소트를 활용할 수 없습니다.
이 문제를 병합 정렬을 활용하여 어떻게 풀 수 있을까요? 아래 포스트에서 확인하실 수 있습니다.
백준 1517번 풀이 보기 : (준비중)